
Coding Memo
구글 프로토버퍼 (Google Protobuf) 패킷 설계 본문
구글에서 제공하는 프로토버퍼를 이용해 서버와 클라이언트간 패킷을 주고받는 시나리오를 계획했다.
서버와 클라이언트 간 전송 시에는 byte[]라는 배열로 주고 받게 되는데, 이 배열을 다시 어떤 객체로 파싱하는 과정이 필요하다.
CustomBuffer (직접 직렬화한 버퍼)를 사용하였을 때는 버퍼의 헤더를 추가하여, 버퍼의 맨앞에 2바이트 타입을 추가하고 그 값으로 전체 패킷의 길이를 넣었고 두번째 2바이트 값으로 해당 패킷의 원래 객체 타입을 정의해서 넣었었다.
아래의 구조와 같이 직렬화하는 버퍼를 CustomBuffer라고 하겠다.

파싱할 때는, 처음 2바이트를 읽어서 단위 패킷의 범위를 정한다.
그 다음으로 2바이트를 읽어서 Body에 있는 데이터를 어떤 객체로 역직렬화할 건지 알아낸다.
마지막으로, 4바이트 이후 부터 패킷끝까지의 데이터를 타입에 맞게 역직렬화한다.
구글 프로토버퍼를 사용할 때도 위의 내용을 활용하는 방법을 생각해 내었다.
참고로 데이터를 메시지(message)라고 표현하겠다. (프로토 버퍼에서는 이렇게 표현한다.)
1. 메시지 자체에 size와 type을 모두 포함시키는 방법
이 방법은 위에 나왔던 패킷의 구조랑 거의 유사하다.
각 메시지 객체의 첫 번째 태그(1)과 두 번째 태그(2)를 각각 size와 type으로 두면 된다.
딱 이렇게 하면 위의 패킷의 구조랑 사실상 똑같다고 생각할 수도 있지만, 파싱에서 문제가 생긴다.
먼저, 프로토 버퍼에서 직렬화가 어떻게 되는지 살펴보아야 한다.
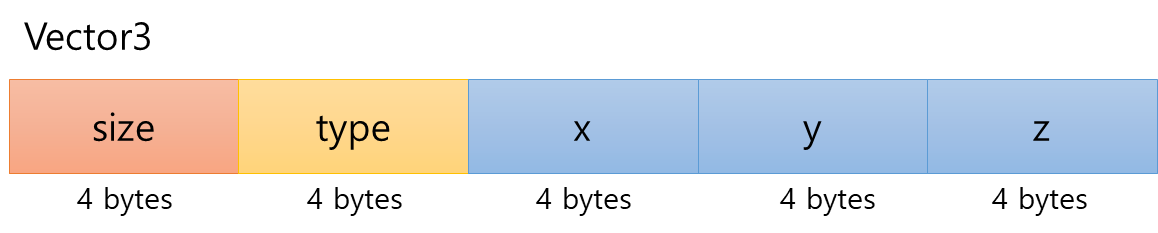
아래 메시지를 직렬화 한다고 해보자. (아래 Vector3 클래스는 protobuf에 의해 생성된 메시지 객체라고 가정하자.)
class Vector3
{
int size;
int type;
int x;
int y;
int z;
}이 객체를 직렬화한다면 우리는 아래와 같이 생각할 것이다.
int => 4바이트
이므로, CustomBuffer처럼 직렬화 시에는 아래 바이트 배열을 만들 것이다.
하지만, 프로토 버퍼는 위와 같이 직렬화 하지 않는다.
기본적으로 각 필드를 직렬화하기 전에 태그를 쓴다.

각 필드를 ? 바이트로 표현했는데, 이 값은 필드의 값에 따라 달라진다!
??? 이게 무슨 말인가?
프로토 버퍼에서 int32, uint32, int64, bool, enum 등의 타입은 직렬화 할때 고정적으로 원래 표현되는 바이트(ex - int: 4바이트)로 직렬화 하지 않는다.
이런 타입들은 Varint 형식으로 직렬화하는데, 이는 값에 따라 1바이트가 될 수도 있고 그 이상이 될 수도 있다.
중요한 부분은 값을 표현하는데 있어서 최소한의 바이트만 사용한다는 점이다.
아래 내용은 varint 형식에 대한 직렬화를 예시로 든 글이다.
varint에서 1바이트로 표현할 수 있는 최대 값은 msb 1비트 제외하고 2^7-1 = 127 이다.
예를 몇개 보자면,
10 => 0 0 0 0 1 0 1 0
18 => 0 0 0 1 0 0 1 0
127 => 0 1 1 1 1 1 1 1
131 => 1 0 0 0 0 0 1 1 | 0 0 0 0 0 0 0 1
10, 18, 127을 표현하는데 있어서 1바이트면 충분하다. 8비트 내에서 10을 표현할 수 있다.
131은 1바이트 내에 표현할 수 없으므로 2바이트로 표현한다.
첫번째 바이트의 msb를 1로 두어서 다음 바이트까지 이어서 파싱하라고 알려주는 방법을 이용한다.
131에서 처음 바이트의 msb가 1이므로 다음 바이트도 이어서 읽으라는 뜻이다.
따라서 msb를 제외하고 값을 확인해보면 된다.

태그 값도 마찬가지로 varint 방식으로 직렬화 된다.
필드 값마다 직렬화 길이가 달라지면, 받은 배열이 어디까지가 하나의 패킷이고 그 패킷이 어떤 클래스(메시지)인지 어떻게 알지?
프로토버퍼는 fixed32의 타입이 있다. 이 타입의 필드는 직렬화 시 고정적으로 4바이트(32비트)로 직렬화 된다.
또한 (protoc에 의해 만들어진 코드를 보면 알겠지만) 태그 값은 처음부터 큰 값으로 시작하지 않는다. 태그 값은 필드 타입에 따라 특정 값이 누적되면서 결정된다.
따라서 가장 처음 필드와 두 번째 필드를 각각 fixed32 타입으로 하면 태그 값은 8이므로, 이 두 가지 필드에 대해서, 태그 길이는 각각 1바이트 (8, 16 이므로)로 표현이 된다.

위와 같은 구조로 메시지를 직렬화하면 역직렬화할 시에, size 값과 type 값을 그대로 가져올 수 있기 때문에 전체 메시지를 원래 객체로 파싱하는데 문제가 없다.
위 방법에 대한 아쉬운 점이 두 가지 있다.
1. 사이즈와 타입을 반드시 4바이트로 표현해야 함 => 패킷 버퍼 낭비
2. 사이즈와 타입도 필드기 때문에 이에 대한 태그가 각각 추가로 직렬화되야함 => 패킷 버퍼 낭비
(솔직히 말해서 패킷 종류가 매우 많지 않아서 short(int16) 안에 다 표현이 될 수 있고, 패킷 하나의 길이가 INTMAX 값을 넘을 것 같지 않다. 프로토버퍼는 short 타입을 지원하지 않아서 낭비가 되는 것처럼 보인다...)
2. 메시지 객체를 wrapper 클래스로 캡슐화 하는 방법
이 방법은 굉장히 간단하다.
일단 1번 방법과 달리 메시지에 타입과 크기를 지정할 필요가 없다. 그냥 단순히 필요한 필드만 넣어서 메시지 객체를 생성하면 된다.
메시지를 wrapper 클래스로 감싼다. 이 wrapper 클래스에는 size와 type, 메시지를 필드로 가지고 있다.

굉장히 심플하다.
메시지를 전송할 때 wrapper 클래스에 담아서 직렬화 후 전송하면 된다.
역직렬화할 때는, 처음 2바이트를 패킷 사이즈로, 다음 2바이트를 타입으로 읽은 후에, 이 이후의 바이트부터 읽었던 타입에 맞게 역직렬화를 해주면 된다. (따라서 받을 때는 Wrapper 클래스를 직접적으로 사용할 필요가 없다.)
위 방법에 대해 아쉬운 점이 2가지 있다.
1.메시지를 그대로 전송할 수 없고 Wrapper 클래스에 넣어서 직렬화해야만 한다.
2. 수동으로 size와 type을 각각 직렬화 하고 그 뒤에 메시지를 직렬화한 버퍼를 붙여야한다.
2번 방법은 생각해 내고 바로 만들어서 테스트 할 수 있었지만...
1번 방법의 경우에 아이디어 자체는 기존 CustomBuffer와 동일해서 바로 생각해 냈지만, Google.Protobuf의 인코딩(직렬화) 방식에 대해 공식문서를 제대로 읽어보지 않고 하나하나 테스트 해보다가 나중에서야 이해해서 상당히 오래 걸렸다.
딱 3가지만 기억하자.
1. 직렬화 시 필드 값을 쓰기 전에 필드 타입에 대한 태그 값을 먼저 쓴다.
2. 만약 필드 값이 0이거나 default 값이면 해당 필드에 대한 값은 직렬화 하지 않는다. (태그도 안쓴다!)
3. 효율성을 높히기 위해 varint를 사용하는데, 이는 값에 따라 직렬화된 바이트 길이가 달라진다.
'etc' 카테고리의 다른 글
| 최대 연속 부분 구간 합 문제 (여러가지 풀이) (0) | 2023.09.12 |
|---|---|
| [C#] Visual Studio 조건부 컴파일 심볼 설정 (0) | 2023.08.15 |
| [C#] 에코 서버 만들기 (0) | 2023.07.03 |
| [C++, C#, Java] 소켓 (Socket) (0) | 2023.07.02 |
| 함수 호출 in stack (0) | 2023.06.25 |