
Coding Memo
BitConverter, 직렬화 (little-endian, big-endian) 본문
BitConverter는 .NET에서 제공하는 API로 기본 primitive 타입들의 데이터를 바이트 배열(byte[])로 직렬화하거나 바이트 배열을 역직렬화하는 기능을 제공한다.
제공되는 Primitive Types
- Boolean
- Char
- Double
- Int16 (short)
- Int32 (int)
- int64 (long)
- Single (float)
- UInt16 (ushort)
- UInt32 (uint)
- UInt64 (ulong)
Note: float형이 Single로 된다는 것을 유의하자.
아래 문서에 자세히 나와 있다.
https://learn.microsoft.com/ko-kr/dotnet/api/system.bitconverter?view=net-8.0
BitConverter 클래스 (System)
기본 데이터 형식을 바이트의 배열로, 바이트의 배열을 기본 데이터 형식으로 변환합니다.
learn.microsoft.com
이번에 주목해야 할 점은 '직렬화 시에 little-endian으로 직렬화를 하느냐, big-endian으로 직렬화를 하느냐' 이다.
위 문서에도 나와 있듯이, 컴퓨터 아키텍처에 따라 달라진다. 이는 다음의 코드를 통해 확인할 수 있다.
static void Main()
{
bool isLittleEndian = BitConverter.IsLittleEndian;
Console.WriteLine($"IsLittleEndian? {isLittleEndian}");
}
BitConverter는 위 값에 따라 big-endian이나 little-endian으로 직렬화한다.
실제로 확인해 보자.
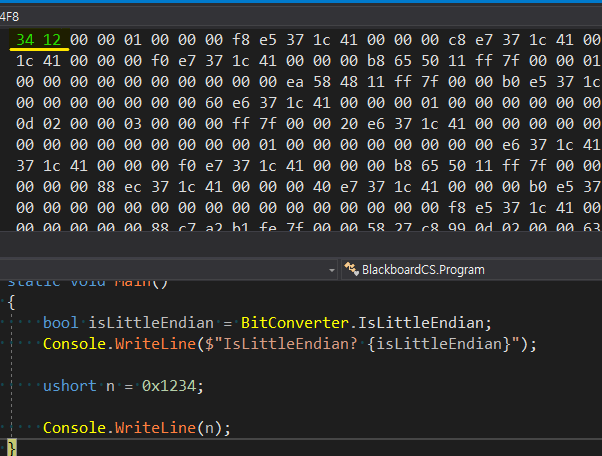
아래 주소값은 &n에 대한 메모리 값이다. (Debug 시, Debug-Windows-Memory에서 확인 할 수 있다.)
n값을 0x1234로 해놓았고, 실제 메모리에서는 '34 12'로 저장되어 있는 것으로 보아 little-endian 방식인 것을 확인할 수 있다.
| examples | memory | ||
| little-endian | 상위 바이트가 앞에 나옴 | 0x12'34 | 34 12 |
| big-endian | 상위 바이트가 뒤에 나옴 | 12 34 |
(byte 단위인 것에 유의하자.)
마지막으로 BitConverter의 GetBytes()함수를 이용해 직렬화된 값은 실제로 어떤지 확인해보자.
class Program
{
public static void PrintBits(byte[] bytes)
{
for (int i = 0; i < bytes.Length; i++)
{
for (int j = 7; j >= 0; j--)
{
Console.Write((bytes[i] & (1 << j)) != 0 ? "1" : "0");
if ((7 - j) % 4 == 3) Console.Write(" ");
}
}
Console.WriteLine();
}
static void Main()
{
ushort n = 0b1111000011000011;
byte[] buffer = BitConverter.GetBytes(n);
PrintBits(buffer); // output: 1100 0011 1111 0000
}
}
출력 결과는 `1100 0011 1111 0000` 이다.
앞에 1 바이트 (1111 0000)가 뒷쪽으로 가있고, 뒤의 1 바이트 (1100 0011)가 앞쪽으로 가있는 것을 확인할 수 있고, little-endian으로 직렬화 된것을 확인할 수 있다.
BitConverter를 이용해 직렬화 하는 대신 좀 더 빠르게 수행하기 위해 비트 쉬프트 연산을 이용해보자.
간단하게 ushort 타입을 예시로 해보겠다. (ushort는 2bytes이고 부호비트가 없다.)
Note: C#에서 정수형 데이터 타입에 대해서만 비트 쉬프트 연산을 할 수 있다. (데이터 보호 차원에서 그렇다.)
(부동소수점를 직접 계산하여 비트로 표현하는 것도 어려운데, 여기서 비트 쉬프트를 한다면 그 의미를 찾기 어려울 것이다.)
public static void PrintHex(byte[] bytes)
{
for (int i = 0; i < bytes.Length; i++)
{
Console.Write("{0:X}", bytes[i]);
}
Console.WriteLine();
}
public static byte[] Serialize_Big(ushort value)
{
byte[] buffer = new byte[sizeof(ushort)];
buffer[0] = (byte)(value >> 8);
buffer[1] = (byte)value;
return buffer;
}
public static byte[] Serialize_Little(ushort value)
{
byte[] buffer = new byte[sizeof(ushort)];
buffer[0] = (byte)value;
buffer[1] = (byte)(value >> 8);
return buffer;
}
public static byte[] Serialize_BitConverter(ushort value)
{
return BitConverter.GetBytes(value);
}
static void Main()
{
bool isLittleEndian = BitConverter.IsLittleEndian;
Console.WriteLine($"IsLittleEndian? {isLittleEndian}");
ushort n = 0xABCD;
var big_endian = Serialize_Big(n);
var little_endian = Serialize_Little(n);
var bitconverter = Serialize_BitConverter(n);
Console.WriteLine("Original Value: {0:X}", n);
Console.Write("Big Endian: "); PrintHex(big_endian);
Console.Write("Little Endian: "); PrintHex(little_endian);
Console.Write("Converter - Little Endian: "); PrintHex(bitconverter);
}

BitConverter대신에 직접 비트 쉬프트를 이용해 직렬화 하는 것은 성능 향상에 도움을 줄 수 있을 것이다. 그러나 어떤 예외를 발생시키지 않고 비트를 직접 컨트롤하기 때문에 데이터 손실 등의 발생할 가능성이 존재한다.
또한 데이터 송수신시에는 (보통은 little-endian이겠지만), 상대방의 역직렬화(deserialize) 방식도 고려해야 할 필요가 있을 수 있다.
Note: C#은 안전하고(?) 고수준의 언어기 때문에 정수형 타입에 대한 쉬프트 연산자로 인한 메모리 오염 문제는 일어나지 않는다. 메모리 범위를 초과할 경우 해당 내용은 다른 영역까지 영향을 미치지 않고 무시된다. 예를들어, byte에 대해 쉬프트 연산자를 사용할 경우 그 결과는 byte 범위 내에서만 유효하고 유지된다. 그러나 잘못된 연산에 대한 데이터 손실문제는 여전히 남아있다.
ex)
0xABCD 값을 little-endian으로 직렬화하면 CDAB가 되고 이를 big-endian으로 역직렬화하면, ABCD가 아닌 0xCDAB값이 되어 엉뚱한 값이 되버린다.
수정 로그
- 23.12.19: 일부 문장 오류 수정; C#의 경우 메모리 오염문제 방지가 되지만 데이터 손실등의 위험은 여전히 있음; C#에서 비트 쉬프트 연산은 정수형 데이터에 대해서만 적용 가능;
'Language > C#' 카테고리의 다른 글
| 라이브러리 xml 문서 생성 (API Documentation) (0) | 2024.01.30 |
|---|---|
| Entity Framework - virtual 키워드 (1) | 2023.12.31 |
| Environment.TickCount 오버플로우 (대안) (0) | 2023.11.29 |
| 싱글턴 멀티 스레드 주의 (1) | 2023.11.23 |
| 에코 서버 (TcpClient, async/await 이용) (0) | 2023.11.09 |