
Coding Memo
[C++] pack pragma (메모리 정렬) 본문
C++ 컴파일러는 메모리에 구조체나 클래스를 배치할 때, 반드시 빈공간 없이 빽빽하게 메모리를 사용하지 않는다.
컴파일러는 CPU의 데이터 접근 효율성 향상을 위해 특정한 값으로 정렬을 하여 메모리에 데이터를 배치시킨다. (데이터 형식에 따른 일정한 간격 유지)
(예를 들어, int 타입의 데이터는 빠른 메모리 접근을 위해 4배수의 메모리 주소에 저장할 것이다. 이로 인해 이전 메모리 공간에 빈 공간 (padding)이 생길 수 있다.)

만약 위 구조체에서 b가 int 타입이 아닌 double 타입이었다면 b를 8바이트 정렬하기 위해 a이후에 패딩을 추가할 것이다.
| a(2) | padding(6) | b(8) |
즉, padding은 다음 순서에 오는 멤버의 데이터의 형식에 따라 존재여부와 사이즈가 결정된다.
다음 멤버의 데이터 형식에 오프셋을 맞출려고 하기 때문이다.
또한 마지막 멤버 이후의 메모리 패딩은 그때까지 나왔던 가장 큰 데이터 형식에 따라 사이즈가 결정된다.
몇 가지 예시를 들어보면,
struct A { short a; int b; double c;}
| a(2) | padding(2) | b(4) | c(8) |
struct A { short a; double b; short c; }
| a(2) | padding(6) | b(8) | c(2) | padding(6) |
struct A { int a; short b; int c; double d; char e; }
| a(4) | b(2) | padding(2) | c(4) | padding(4) | d(8) | e(1) | padding (7) |
CPU 아키텍쳐나 컴파일러에 따라서 정렬하는 사이즈가 달라질 수 있다.
(컴파일러에 별다른 옵션을 설정하지 않으면, CPU에 따라 달라질 것이고, 해당 자료형의 크기에 따라 달라질 것이다.)
(보통은 64비트에서는 16, 32비트에서는 8이다.)
`#prama pack`은 메모리 정렬 사이즈(byte)를 지정할 수 있도록 해준다.
간단한 사용방법은 다음과 같다.
| 구문 | 설명 |
| #pragma pack([n]) | 이후에 나오는 메모리 배치를 n 바이트 단위 압축하도록 설정한다. |
| #pragma pack() | 이후에 나오는 메모리 배치를 default 값으로 바꾼다. |
| #prama pack(push, [n]) | 이후에 나오는 메모리 배치를 n 바이트 단위로 바꾸고 이전 상태(이전 메모리 배치 상태)를 (내부 컴파일러)스택에 push하여 저정한다. |
| #pragma pack(pop) | (내부 컴파일러) 스택에서 상태를 pop하고 그 pop된 값으로 메모리 배치 상태를 설정한다. |
아래에 identifier를 설정하는 등의 설명이 나와있으므로 참고하자.
https://learn.microsoft.com/ko-kr/cpp/preprocessor/pack?view=msvc-170
팩 pragma
Microsoft C/C++의 pack pragma 지시문에 대해 자세히 알아보기
learn.microsoft.com
*** Note: 간단히 말해서 pack(n)은 단순히 하드하게 이후 메모리 정렬을 강제하는 것이고, pack(push) 및 pack(pop)은 이전 상태를 저장하고 불러오는 기능이다. 자신의 코드만 짧게 사용한다면 전자를 사용해도 상관없지만, 좀 더 안전하게 후자를 이용하는 것도 좋은 방법이다. 강제로 설정하면 메모리 배치를 바꾼 상태에서 다른 라이브러리나 다른 코드들에 영향을 미칠 가능성이 높기 때문이다.
메모리 레이아웃
다음 구조체가 실제로 어떻게 메모리에 배치되는지 레이아웃을 살펴보자.
struct monster {
char mid; // 1 byte
int id; // 4 bytes
short num; // 2 bytes
};
먼저 pack을 하지 않았을 경우에는 다음과 같이 메모리 레이아웃을 가질 것이다.
(int가 4byte 정렬이라고 했을 때)
| mid(1) | padding(3) | id(4) | num(2) | padding(2) |
id가 int 값으로, 4바이트 정렬을 위해서 컴파일러는 id 값을 메모리에 배치하기 전에 padding을 추가한다. 위에서는 mid가 char 타입으로 1바이트 이므로 3바이트의 padding을 추가했다. (즉, padding은 mid에 의해 생긴것이 아니라, mid 이후의 id의 타입에 의해 생긴 것이다.)
num이후에도 int의 4바이트에 맞추기위해 2바이트의 패딩이 추가된다.
1+4+2=7로 위 구조체는 7바이트의 공간을 차지할 것 같지만, 실질적으로는 패딩을 포함하여 1+3+4+2+2=12로 12바이트의 공간을 차지하게 된다.
pack(1)을 이용하여 1바이트로 정렬 (바이트단위로 빈 공간 없도록)했을 때의 레이아웃은 다음과 같다.
#pragma pack(push, 1)
struct monster {
char mid; // 1 byte
int id; // 4 bytes
short num; // 2 bytes
};
#pragma pack(pop)
| mid(1) | id(4) | num(2) |
위와 같이 1바이트 정렬을 하게 되면 monster 구조체는 7바이트의 메모리 공간을 가질 것이다. pack을 하지 않았을 때와 비교하면 더 적은 메모리 공간을 가질 수 있다. 추가적으로 위 메모리 레이아웃은 구조체 monster를 직렬화한 결과와 같다!!
이번엔 각각 2, 4, 8, 16에 대해 정렬을 해보자.
#pragma pack(push, 2)
struct monster
{
char a;
int b;
short c;
};
#pragma pack(pop)
// result
// | a(1) | padding(1) | b(4) | c(2) |
// size: 8
2바이트 정렬 시, int가 왔음에도 불구하고 a뒤에 1바이트만 패딩으로 추가된 것을 알 수 있다.
4, 8, 16에서의 결과는 모두 같다.
#pragma pack(push, 4)
struct monster
{
char a;
int b;
short c;
};
#pragma pack(pop)
// result
// | a(1) | padding(3) | b(4) | c(2) | padding(2) |
// size: 12
int가 결과적으로 최대 크기의 데이터 형식으로 4바이트로 정렬될 것이다.
***Note: 메모리 정렬은 배열에서도 똑같이 적용된다. 예를 들어 int 값 이전에 길이가 10인 char 타입인 멤버가 있다고 가정하자. 그렇다면 처음 10바이트를 이 맴버가 사용할 것이고 이후, 컴파일러는 int값인 멤버를 메모리에 놓기위해 2바이트의 padding을 추가한 후에 그 멤버를 배치할 것이다. (물론 이 padding도 환경에 따라 추가가 될 수도, 안될 수도 있다.)
| char a[10](10) | padding(2) | int b(4) |예제 코드
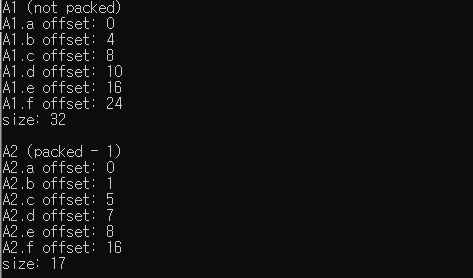
offset까지 확인해보자.
using namespace std;
#pragma pack(show) // 32bit: 8; 64bit: 16
struct A1
{
char a;
int b;
short c;
char d;
double e;
char f;
};
#pragma pack(push, 1)
struct A2
{
char a;
int b;
short c;
char d;
double e;
char f;
};
#pragma pack(pop)
int main()
{
printf("A1 (not packed)\n");
printf("A1.a offset: %zu\n", offsetof(A1, a));
printf("A1.b offset: %zu\n", offsetof(A1, b));
printf("A1.c offset: %zu\n", offsetof(A1, c));
printf("A1.d offset: %zu\n", offsetof(A1, d));
printf("A1.e offset: %zu\n", offsetof(A1, e));
printf("A1.f offset: %zu\n", offsetof(A1, f));
#if defined(_WIN64)
printf("size: %llu\n", sizeof(A1));
#else
printf("size: %u\n", sizeof(A1));
#endif
printf("\n");
printf("A2 (packed - 1)\n");
printf("A2.a offset: %zu\n", offsetof(A2, a));
printf("A2.b offset: %zu\n", offsetof(A2, b));
printf("A2.c offset: %zu\n", offsetof(A2, c));
printf("A2.d offset: %zu\n", offsetof(A2, d));
printf("A2.e offset: %zu\n", offsetof(A2, e));
printf("A2.f offset: %zu\n", offsetof(A2, f));
#if defined(_WIN64)
printf("size: %llu\n", sizeof(A2));
#else
printf("size: %u\n", sizeof(A2));
#endif
return 0;
}
Result
직렬화
위에서 언급했지만, 1바이트로 정렬한 메모리 레이아웃은 해당 구조체나 클래스를 직렬화한 레이아웃이랑 같다. 이를 이용하여 추가적인 직렬화 과정없이, 그대로 네트워크 상에서 데이터를 저장하거나 전송할 수 있다.
memcpy등을 이용하여 압축된 해당 구조체나 클래스의 포인터나 주소값을 복사하여 버퍼에 바로 쓰면 유용하다.
마찬가지로, 버퍼에서 데이터를 읽을 때, 해당 구조체로 역직렬화하여 사용할 수 있다.
'Language > C++' 카테고리의 다른 글
| [FlatBuffers] nested 에러 (nested was true) (0) | 2024.03.11 |
|---|---|
| [C++] 가상 소멸자 (0) | 2024.03.06 |
| Use After Free (0) | 2023.11.02 |
| 값 범주 (value categories) (rvalue, lvalue, xvalue) (0) | 2023.10.27 |
| Visual Studio glog 사용 (2) | 2023.10.26 |

